


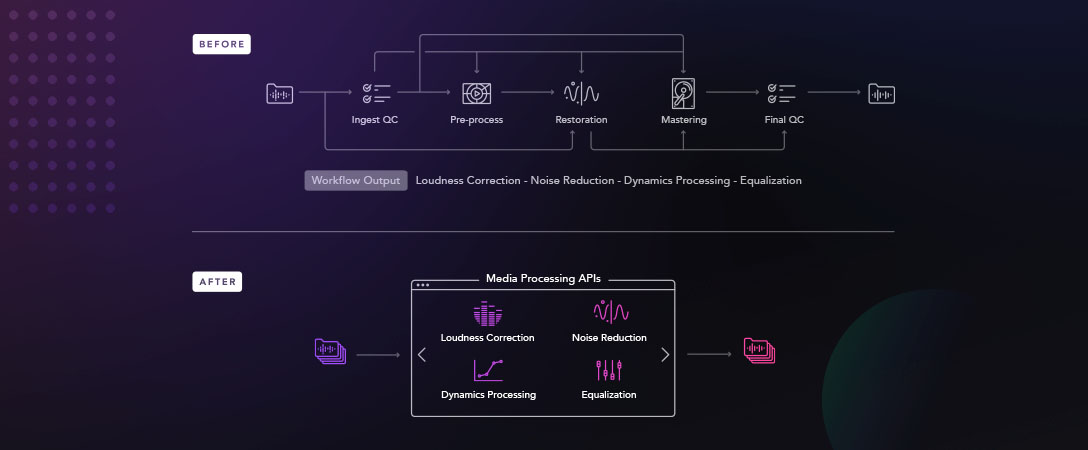
The Dolby.io Media Processing APIs are composed of a series of processing steps that have been fine-tuned to identify and improve the vocal clarity of audio. Giulio Cengarle is a Sr. Staff Researcher at Dolby Laboratories who answered some questions to help share insight into how the Media Enhance API works.
Giulio, first tell us a bit about yourself
Giulio Cengarle:
I did undergrad studies in Physics at the University of Trieste, Italy, and got my Ph.D. from the Universitat Pompeu Fabra, Barcelona, with a thesis on 3D-audio technologies. In parallel, I studied music and worked as a recording engineer. This background led to my current role as Sr. Staff Researcher at Dolby, where I work on technologies for music and speech within a team of very skilled colleagues.
In addition to a love of music and audio, I enjoy photography and sports.
What is a speech enhancement chain?
It can be helpful to think of speech enhancement as a series of steps, one coming after another, each dedicated to improving a specific aspect of speech, with the overall goal of delivering the best possible intelligibility and sound quality. Technically there are some steps which can be done in parallel rather than purely serial, but generally each link in the chain will detect a particular type of speech impurity and then make enhancements or corrections to remove or reduce the impact of the unwanted sound, and to make the recording sound more professional.
There are also a few early steps that analyse the content and provide essential information to other links further down in the chain.
In the production of speech content – things like podcasts, audio books, interviews, and lectures – the raw recordings are edited and processed to comply with the standards of quality that people have been accustomed to in broadcasting, and to guarantee a proper listening experience on a variety of devices. This job is often carried out by skilled sound engineers using their own “speech enhancement chain” consisting of analogue or digital processing devices which may include hardware, software, or a combination of both.
With increasing amounts of content being generated, it is valuable to provide tools for automating and speeding up the editing and processing stages, while still guaranteeing a professional quality of speech, with naturalness and intelligibility.
What is an example of a speech impurity?
Take for instance hum. A hum is a constant noise (or near-constant) with outstanding tonal components. This can come from a range of sources such as the 50Hz + harmonics noise from electric lines, or the acoustic noise of air blowing through the HVAC pipes.
We have a De-Hum step that would estimate peak frequencies in the noise spectrum and then subtract them frame-by-frame, effectively removing the hum. This is one of several noise removal steps we apply to the audio.
What other types of noise removal are done?
The heavy-lifting is done by neural networks that have been trained to distinguish speech from noise, and to suppress the noise: this is something that could only be dreamt-of until recent years!
We combine these advanced techniques with something simpler based on well-known industry practice and common sense, and a High-Pass filter is a good example. The filter acts to remove low-frequency components in the audio, anything below 80Hz where vocal frequencies are not present. This is typically used in most vocal and speech recording chains to reduce noise, rumble, etc.
This is something we apply early in the chain so that the rest of the algorithms have an easier job to do. In fact, any undesired sounds outside the speech range are better cleaned with a filter than other processing tools.
With speech, how do you remove vocal noise?
Generally we have specific algorithms that combine a detection stage with a correction stage; a few examples include De-plosive and De-esser steps.
De-plosive works to remove plosive sounds which are bursts of air that exits the mouth and is picked up by a microphone in close proximity to the talker in an undesirable way, typically as a low-frequency thump. This is common with the “p” and “t” consonants in many words. The algorithm will detect these bursts and flag the regions where a smart filter is applied in order to restore the natural speech sound.
Our chain also includes a De-esser which detects and suppresses sibilance. With sibilance, unusual onsets of energy are picked up by recording devices in a way that is atypical of a normal face-to-face interaction. When sibilance is detected, the algorithm attenuates that energy in the appropriate band proportional to the amount of detected sibilance. The specifics get more complex, but that’s more or less the general idea.
What other categories of enhancement should I listen for?
The area of Dynamics and Loudness is another interesting category that is important to consider as part of our processing chain.
We have a Leveling step that uses the speech sections identified by a sort of voice activity detection to apply time-varying gain so that speech levels are brought within a desired dynamic range, which is the difference in loudness that can be observed between the soft and loud parts of recorded speech. This has some basis on standards such as EBU R128, and the broadcasting industry best practices; leveling is used to keep the target range between 9dB and 6dB and anything outside that range is attenuated or amplified to bring it within the boundary. Frames within the dynamic range are treated with smaller gains to maintain relative balance to other adjustments that were made.
Another area for the enhancement chain is Dynamic Equalisation, which analyses the tonality of the content and, if necessary, corrects its frequency content dynamically, to ensure it matches a reference tonality.
An important final step is Loudness Normalization, where we ensure that the overall signal level complies with a standard loudness; this ensures that you can play a sequence of files processed with our chain without having to adjust a volume control to ensure homogeneous loudness. When high loudness levels are required, we use a transparent, high quality peak-limiter to ensure absence of clipping and distortion.
What are some areas continuing to make rapid improvements in the API?
We are lucky to have so many talented researchers around the company, hence there are always plenty of ideas waiting to move from the whiteboard to our production servers.
The field of Noise Reduction using Deep Neural Networks is in constant progress, with new algorithms being trained to deal with increasingly challenging noise types and amounts, while getting better and better at preserving or reconstructing the underlying speech signal.
Colleagues are working in the area of De-reverberation. Natural reverberation is due to reflections of sound emitted by the source as sonic waves bounce around the environment and are picked up by the microphone after the direct sound from the source. This can be perceived as a “tail” of the sound and is heavily influenced by characteristics of the recording space. Under ideal studio recording conditions, reverberation is either unnoticeable or pleasant, but with speech content from a variety of environments sometimes we hear dramatic differences in the amount and quality of reverberation, with potential negative impact on intelligibility, hence the need to reduce the perceived reverberation by attenuating the unwanted reverb relative to the direct sound.
Where can I learn more?
You don’t need to know the details in order to get good quality audio. Many of these steps include parameters that can be used to customize the behavior of the Media Enhance API. You can find those settings from the documentation or let the chain make an attempt just by specifying the type of content.
You do really need to listen to experience though, which we’ve tried to make easy with our online demo with your own media.




")