



This is a guest post from Javonnii Curry, an audio engineer, data scientist, programmer, and among other things, a former United States Army diver. Earlier this year, Javonnii walked away with the top Dolby.io prize at BrickHack, the annual Rochester Institute of Technology hackathon. What follows is an overview of his winning submission, in which he used Dolby.io Media Processing APIs to help enhance undersea audio to identify the creatures living there.
The Project
You may not realize, but there are passive acoustic instruments (hydrophones) continuously recording sounds in the ocean. As sound travels very efficiently underwater, some species of marine life can be heard many miles away and even across entire oceans. This data provides valuable information that helps government agencies and industries understand and reduce the impacts of noise on ocean life.
I wanted to use this publicly available data, in conjunction with the Dolby.io Media Processing APIs, to visualize the difference between these animals. By researching underwater environment data, we can learn more about migration patterns, animal behavior, and how they communicate.
About the Data
In this project, I scraped audio files from the Watkins Whale Database and the Monterey Bay Aquarium Research Institute Freesound. Check them out if you want to learn more, they’re great resources for marine mammal data.
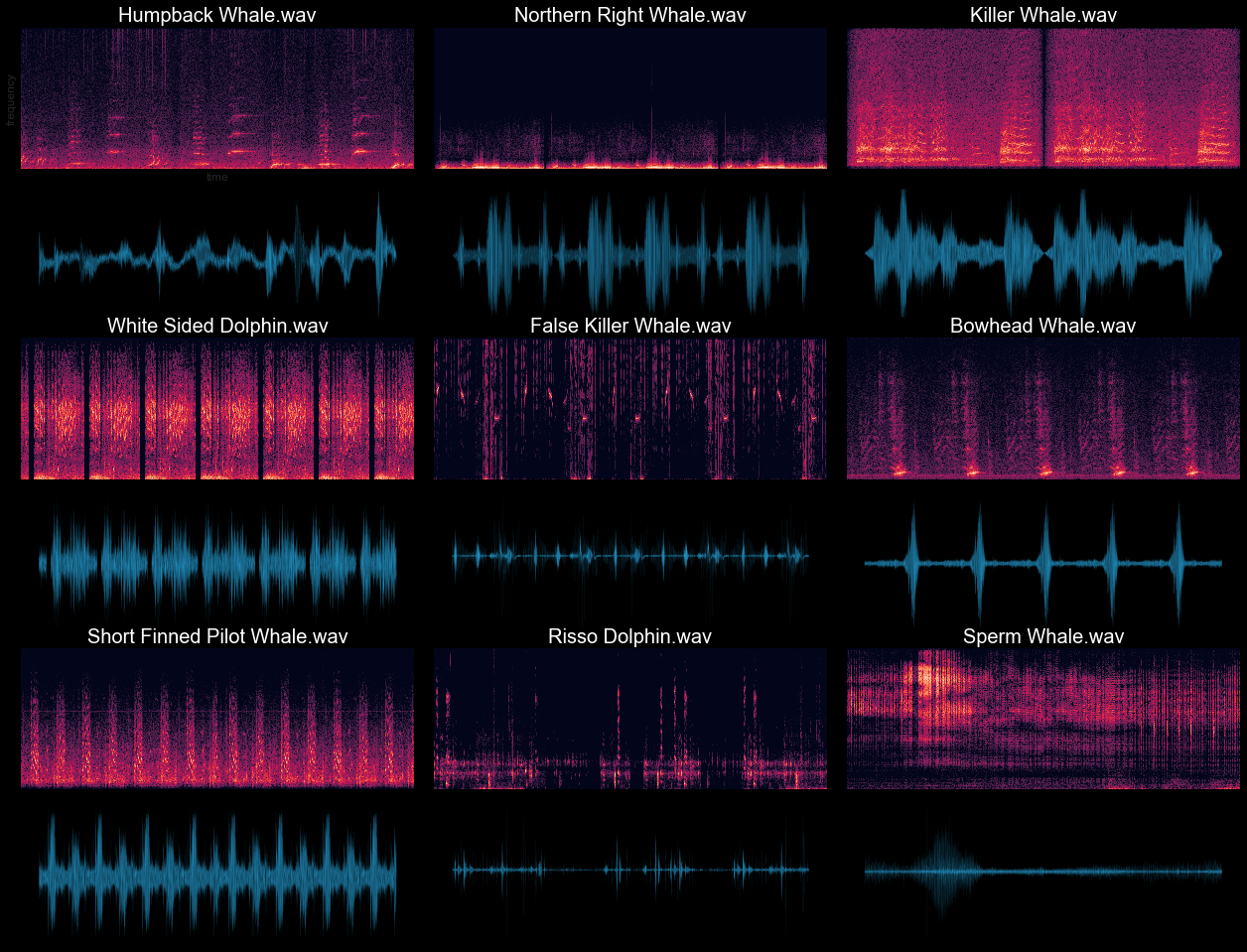
Based on the available data, I built a taxonomy that classifies nine specific marine mammals:
- Killer Whale
- False Killer Whale
- Bowhead Whale
- White-Sided Dolphin
- Risso Dolphin
- Northern Right Whale
- Humpback Whale
- Sperm Whale
- Short-Finned Pilot Whale
Here’s the waveform data I started with:
Creating the Dataset
I sliced each audio file into 30-second clips. Audio files that were longer than 30 seconds were decomposed into lexngths of 30 seconds clips which synthesized more data.
Next, I duplicated all of the audio files in each class and augmented those halves to synthesize more data. I then randomly augmented each file.
The Dolby.io Enhance API proved to be simple and reliable when processing all this audio at scale. In fact, I was able to upload, enhance, and download over 1,200 audio clips.
The enhancement brought out clarity and tonal characteristics in the taxonomy of marine mammals while keeping the noise floor at a minimum.
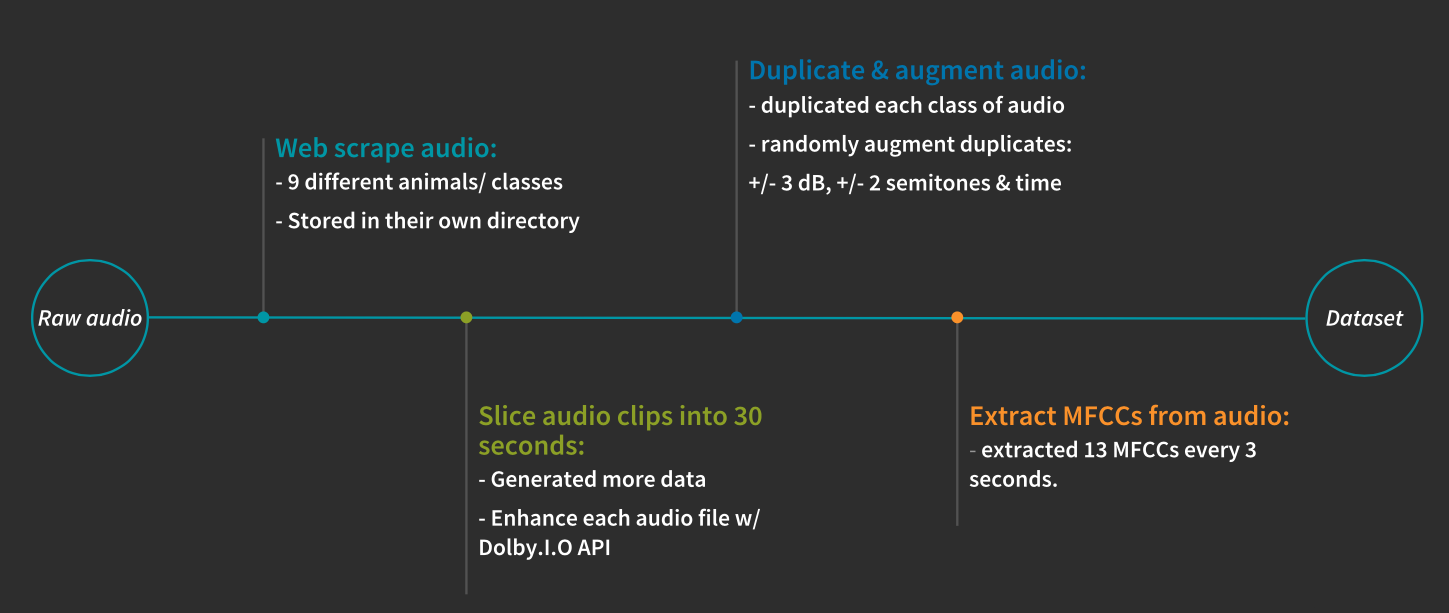
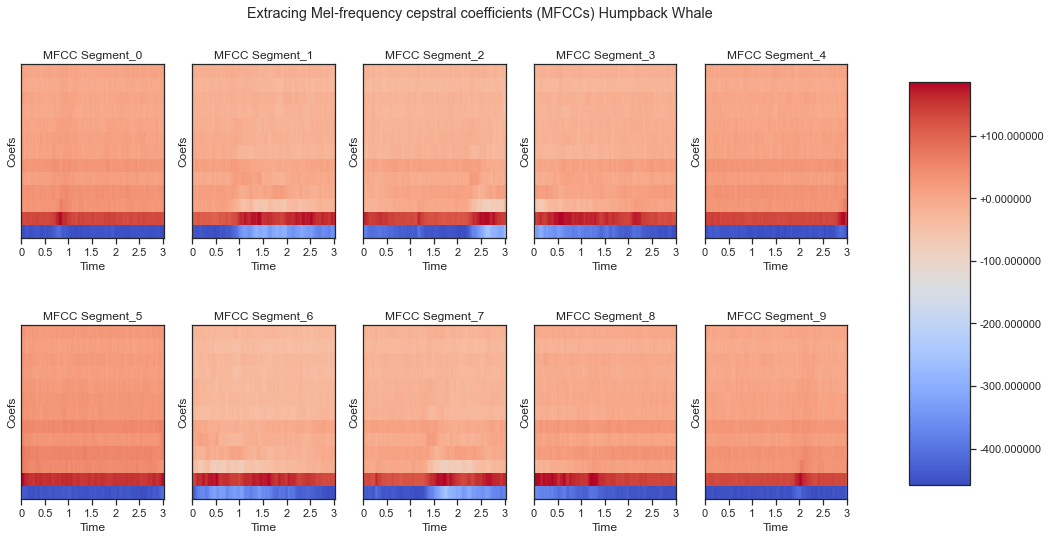
Next, I needed to transform the waveform dataset to have MFCCs (audio feature choice for speech recognition and identification) images and their corresponding labels as integers IDs. I extracted 13 MFCCs for every 30 seconds of audio, per sample.
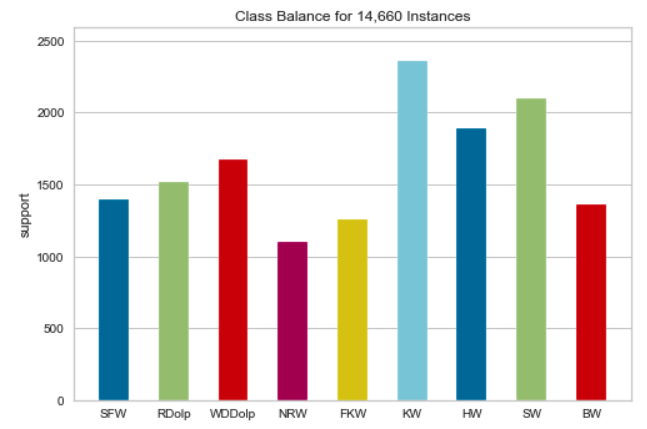
This resulted in a dataset of over 14,000 (!) instances. I created a bar graph to show the distribution.
The next steps were to build and train a Convolutional Neural Network using the dataset. Here’s an example of the model:
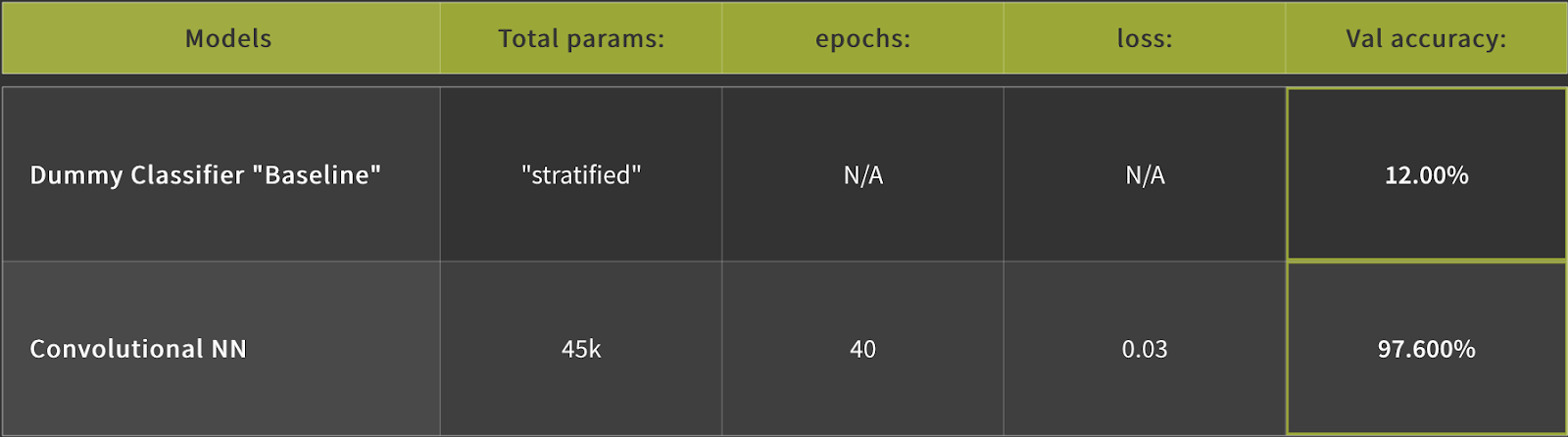
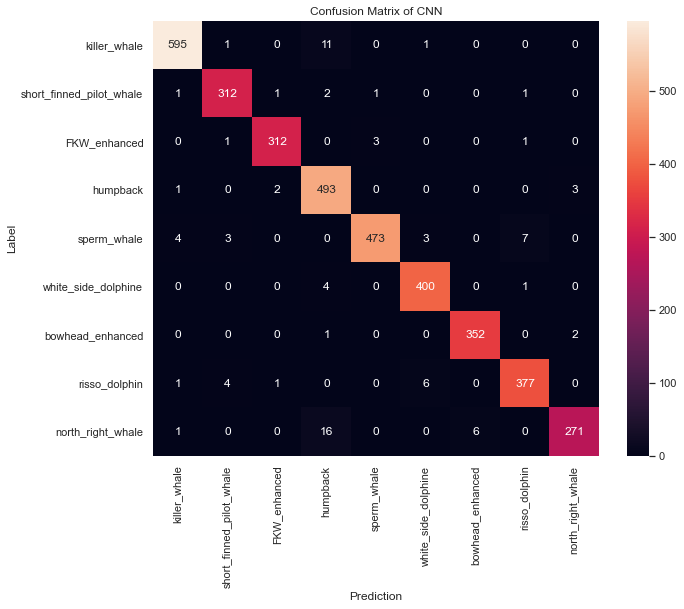
To see how well the model did on each marine mammal in the data set, I then mapped the data to a Confusion Matrix:
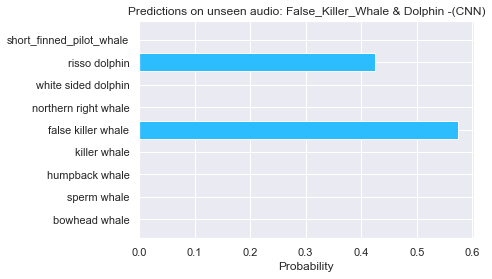
Finally, it was time to verify the model’s predictions using input audio from outside the dataset. I utilized this 30-second audio clip, courtesy of the Centre for Marine Science & Technology (CMST), which consists of audio from both false killer whales and dolphins, to see how well the model would perform.
As you can see in the image below, the model clearly recognizes two sources in that audio file as coming from the false killer whale and a species of dolphin. Overall, the model has a 97% accuracy rate.
In the future, I’d like to add more marine mammal data to really test the limits of the model. Additionally, I’d like to introduce human-generated sounds like the audio created from seafaring vessels and cargo ships, just to see how accurate I can get the model. Another option is implementing real-time analysis using an audio library like Essentia.
In the meantime, if you’d like to learn more about this project please check out these resources:
If you’re looking for a reliable and easy-to-use method of enhancing audio at scale, check out the Dolby.io Media Processing APIs





")