


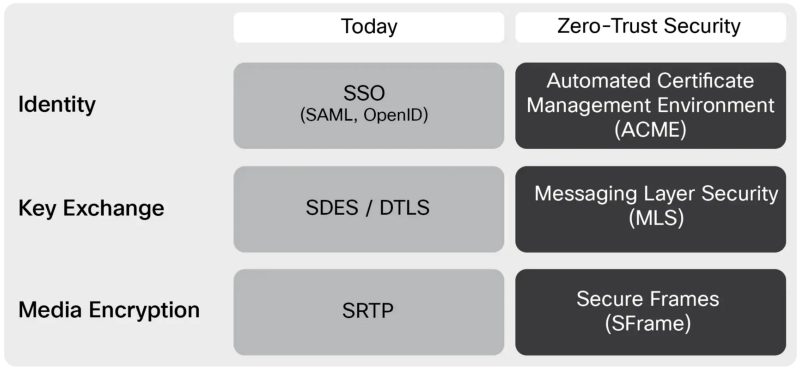
Cisco has just released a White Paper on Zero-Trust Security for Webex, announcing it will implement Secure Frames (SFrames) end-to-end encryption (E2EE) technology for Webex.
Cisco’s Webex joins Google’s Duo and CoSMo’s Millicast as the only products and platforms to support the latest SFrame E2EE and real-time AV1.
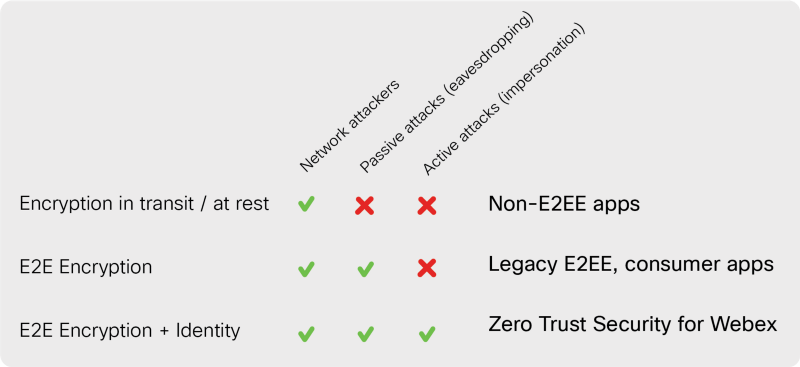
Due to recent events, E2EE has become a must-have in any real-time video service, even if it does not offer privacy or security as it’s main use case. SFrames enables provides a solution for E2EE for WebRTC in SFU scenarios.
For several years we has been providing fully WebRTC compliant end-to-end encryption solutions to clients, including Symphony Communications, using an early modified version of PERC called PERC-lite.
SFrames is the Story of three years of work, by multiple partners:
- 12-MAY-2020: The original (2017) draft for PERC-Lite has been uploaded as an informal IETF Draft here.
- 19-MAY-2020: A more recent and more formal version of SFrame has been uploaded as a standard track IETF draft here.
There are many more customers using the second generation of SFrame that was co-developed originally by Google, including the real-time streaming platform Millicast for customers in need of something better than DRM (Digital Rights Management).
The only catch is that it would not work natively in web browsers. For most mobile apps this was not a problem, and Google Duo has been leveraging it for over a year. But without web browser support, it was less than ideal. So earlier this year Google Chrome added support for SFrame in the browser.
In this post we will give you some technical details about SFrame, how it improves on PERC and provides a free, open-source working example, with an E2EE ready SFU.
The workflow does not match the quality you can get from the full CoSMo E2EME packages, and doesn’t offer the best solution for key exchange, but it does illustrate the concept.
I. Why E2EME (End-to-end media encryption) with WebRTC?
WebRTC was designed for point-to-point, or peer-to-peer connections. It has the strongest, uncompromising security one can have at the time of definition. Unfortunately, there are a lots of things that only become possible when you add a media server in between two, or more, peers.
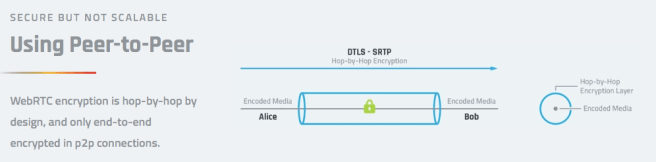
The original WebRTC security was designed for a point-to-point connection, one ‘hop’, and not multiple hops between peers. Keeping the media protected by WebRTC in a multi-hop environment exposes the content to all the media servers in-between.
Your media is still protected over the wire, but if you do not trust the intermediate media servers you are left to define a new security scheme that would protect the content from being accessed. Nevertheless, the media servers still have a job to do, so you need to be able to secure the content in such a way that the media server can still relay media to multiple recipients.
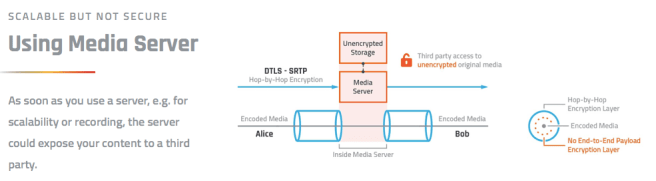
The idea here is to define a new end-to-end encryption and authentication schema for media frames which could be used in addition to WebRTC encryption (without replacing it), in any case where one (conference) or multiple (cascading, clustering, broadcasting) media servers (SFU) will have access to the metadata in order for it to work without getting access to the media. It allows for customers to use platforms without trusting them. It also allows for customer to use their own keys!
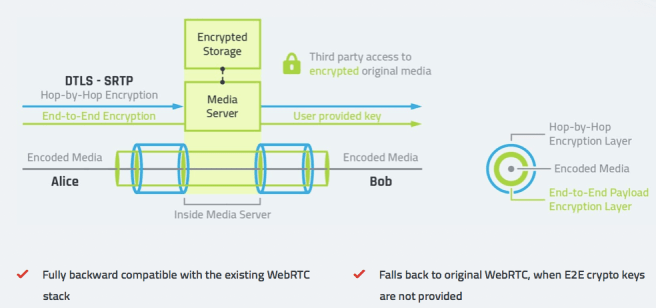
II. Secure Frames: a Media Frame encryption and authentication scheme for WebRTC
In this post, the following acronyms will be used with the corresponding meaning:
- SFU: Selective Forwarding Unit (AKA RTP Switch)
- IV: Initialization Vector
- MAC: Message Authentication Code
- E2E: End to End (AKA Inner Encryption)
- HBH: Hop By Hop (AKA Outer Encryption, AKA HopBop)
An extremely simplified presentation was made during W3C TPAC meeting in Lyon, France toward the end of 2018. The slides are available here.
Obviously WebRTC (DTLS-SRTP) will be kept for HBH encryption. Think about a door with a very good, strong and secure lock. The idea is to add a second one. Whether it is stronger than the first one or not does not matter, since in the worse case scenario the original lock is already there.

The idea is to use the entire media frame instead of individual RTP packet as an encryptable unit to both decrease the encryption overhead and remove the dependency to RTP PERC by default. It also has the added side effect to mess with different RTP feedback mechanisms, and addresses many of the shortcoming that PERC would allegedly suffer from. Note that not depending on RTP allow for this approach to be used with Datachannels, or web sockets, or QUIC ….. making it future-proof.
Using a media frame level encryption schema for the E2E layer allows to use only a single IV and MAC per media frame and not per RTP packet. Since there are multiple RTP packets for a given media frame, we should achieve lower overhead bandwidth usage
Design: SFrame Keys
- E2E encryption keys are exchanged between the endpoints out-of-bands using a secure channel, for example MLS.
- E2E keys should be changed whenever endpoints joins or leaves the call
- Similar to SRTP, three keys are derived from the E2E master key
- Salt key
- Encryption key
- Authentication key
- The RTP headers and header extensions are not authenticated end-to-end, SFUs are partially trusted to read and modify them.
- The metadata required by SFUs is available in the RTP header extension, ideally by moving them from the payload to a generic payload metadata extension to avoid duplicating them for each RTP packet corresponding to the same media frame.
- E2E IV is derived from a variable length frame counter which is included at the beginning of the first RTP packet of the frame.
- E2E uses 32bits MAC for audio frames and 80bits for video frames
- HBH uses 32bits MAC for both audio and video packets.
- Receiver endpoints can’t decode partial frames because they will have to wait for all packages of the frame to verify the MAC and decrypt it.
Design: SFrame Encryption Schema

In SFrame packets, the codec specific payload header will be moved to a generic payload header extension that is HBH authenticated , and could be HBH encrypted (Recommended) but not E2E encrypted nor authenticated.
The SFrame payload is constructed by a generic packetizer that splits the E2E encrypted media frame into one or more RTP packet and add the SFrame header to the beginning of the first packet and auth tag to the end of the last packet.
The media payload will be encrypted , the media payload and SFrame header will be authenticated. The entire SFrame payload (header, media and auth tag) will be encrypted again for the HBH.
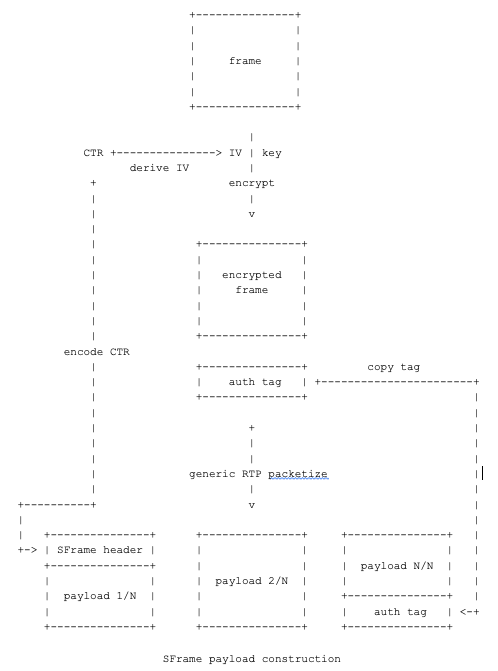
Design: SFrame header
Since each endpoint can send multiple media layers, each stream will have a unique frame counter that will be used to derive the encryption IV. To guarantee uniqueness across all streams and avoid IV reuse, the frame counter will have be prefixed by a stream id which will be 0 to N where N is the total number of outgoing streams.
The frame counter itself can be encoded in a variable length format to decrease the overhead, the following encoding schema is used
- LEN (4 bits)
The CTR length fields in bytes. - SRC (4 bits)
4 bits source stream id - CTR (Variable length)
Frame counter up to 16 bytes long
The IV is 128 bits long and calculated by the following:
IV = (SRC||CTR) XOR Salt key
Design: SFrame Encryption
Each frame is encrypted with a unique IV using AES_CTR amd MAC using HMAC-SHA256. Then the encrypted frame is split into multiple RTP packets using a generic RTP packetizer, and the encoded frame counter is added at the beginning of the first packet payload, while the MAC is added to the last packet of the frame payload
Design: SFrame Decryption
When an endpoint receives all packets of a frame, it uses a generic RTP depacketizer to reconstruct the encrypted frame, Verifies the MAC code, then uses the frame counter in the encryption header to calculate the IV and decrypt the frame.
III. Bandwidth Overhead
The encryption overhead will vary between audio and video streams, because in audio each packet is considered a separate frame, so it will always have extra MAC and IV, however a video frame usually consists of multiple RTP packets.
The number of bytes overhead per frame is calculated as the following
1 + FrameCounter length + 4
The constant 1 is the frame counter header that has the srcId and frame counter length. The MAC length is constant 4 bytes even for video that uses 10 bytes length MAC because we assume the outer encryption will always use 4 bytes MAC length
Audio overhead test.
Using three different audio frame durations
- 20ms (50 packets/s)
- 40ms (25 packets/s)
- 100ms (10 packets/s)
Up to 3 bytes frame counter (3.8 days of data for 20ms frame duration) and 4 bytes fixed MAC length.
Video Overhead test
The per-stream overhead bits per second as calculated for the following video encodings:
- 30fps@1000Kbps (4 packets per frame)
- 30fps@512Kbps (2 packets per frame)
- 15fps@200Kbps (2 packets per frame)
- 7.5fps@30Kbps (1 packet per frame)
Overhead bps = (Counter length + 1 + 4 ) * 8 * fps
Bandwidth: SFrame vs PERC-lite
PERC has significant overhead over SFrame because the double encryption (double SRTP) overhead is per packet, not per frame, and because of OHB which duplicates any RTP header/extension field modified by the SFU.
PERC-Lite ( cosmo/jitsi/symphony article with focus on simulcast, cosmo/janus article, yes 3 years already!) is slightly better because it doesn’t use the OHB anymore, however it still does per packet encryption, running srtp-like encryption on packets payloads.
Below is an illustration of the overhead in PERC_lite implemented by Cosmos Software which uses extra 11 bytes per packet to preserve the PT, SEQ_NUM, TIME_STAMP and SSRC fields in addition to the extra MAC tag per packet.
OverheadPerPacket = 11 + MAC length Overhead bps = PacketPerSecond * OverHeadPerPacket * 8
Similar to SFrame, we will assume the MAC length will always be 4 bytes for audio and video even though it is not the case in this PERC-lite implementation
IV. The Media Server Point of view.
So, from the client side, implementing SFrame is relatively easy, and most has been done in libwebrtc already.
- Private: Implement Sframe encryption/decryption as a standalone library
- Public: Implement a generic frame encryption/decryption API (here)
- Public: Use new RTP header extension for codec-agnostic (“generic”) video description for all (currently supported) video codecs
- Public: Use new “generic” RTP packetization format.
From the SFU, it all depend on the codec. While original implementation only supported VP8, cosmo worked on VP9, and SVC support, thanks to it’s medooze server, the same used by several browser vendors to test compliance with Simulcast, SVC, and more recently AV1 (later this week folks!).
SFrame for VP8

The RTP generic video header extension can also be authenticated by SFrame so that it can’t be modified by the SFU. We have flexibility there.
As only VP8 was supported by the generic video header extension at the time of the design, SFrame could only be used with VP8. Encrypted frames are sent using standard VP8 RTP packetization, and not a generic RTP packetizer.
As a result, the RTP packet, using VP8 packetization contains the RTP VP8 payload description in “clear” and the RTP VP8 payload header and VP8 payload, encrypted.
SFU can use the VP8 payload descriptor as normal, but just like with PERc and PERC-Lite it’s missing the I-frame bit which is in the now-encrypted VP8 payload header. One old solution was to use the FrameMarking RTP Header extension draft, nowadays the new Dependency Descriptor, standardised in the scope of the AV1 effort at AOMedia, provides the equivalent feature.
SFrame for VP9 with SVC support.
Extending SFrame support to VP9 was relatively easy. Similar to what was done for VP8, cosmo used the standard RTP packetization for VP9.

As in VP8 case, the VP9 payload description is available (after DTLS/SRTP decryption) in clear for the SFU, which can run as usual. But unlike VP8, all the info required for an SFU to operate is contained in the VP9 Payload Descriptor, which is NOT encrypted by SFrame by default. Supporting VP9 is thus practically easier than supporting H264 and VP8. For VP9 a Video description extension header is thus not needed.
Even better, NO modifications to most of the webrtc SFU are required at all. Of course, side features like recording will require some modification, but in its core role of proxying and fanning out media stream, no modification are needed.
A small change to libwebrtc was required to remove restrictions of using the Video description extension header with frame encryptor/decrypt, which is only actually required if the authentication experiment was in use ( see this patch from january 2019, jesus, we’re not getting younger …).
VP9 SVC support
Luckily, the VP9 payload description also provides hints for an SFU to decide which frames may be dropped or not according to the desired temporal and spatial layer it decides to send to each endpoint.
The main bits of the payload description that we will be needed to check are:

- P: Inter-picture predicted layer frame, which specifies if the current layer frame depends on previous layer frames of the same spatial layer.
- D: Inter-layer dependency used, which specifies if the current layer frame depends on the layer frame from the immediately previous spatial layer within the current super frame.
- U: Switching up point, which specifies if the current layer frame depends on previous layer frames of the same temporal layer.
It is possible to up-switch up to a higher temporal layer on a layer frame which S bit is set to 0, as subsequent higher temporal layer frames will not depend on any previous layer frame from a temporal layer higher than the current one. When a layer frame frame does not utilize inter-picture prediction (P bit set to 0) it is possible to up-switch to the current spatial layer’s frame from the directly lower spatial layer frame.
Talk is cheap, show me the code!
If you read so far into the post, you deserve to play with a new toy. We are going to provide full code, client and server for you to educate yourself, understand the mechanism, and leave with elevated understanding of the tech. Hopefully, you would cite us, and do business with us, as there is much, much more where this comes from.
At one of the last W3C webrtc working group meeting, Harald A. from google presented his plan for insertable streams updated from a previous conceptual presentation.
The main use case was to support a “client” that needs e2ee to interoperate with its conferencing server and corresponding native apps which support it already. Supposedly, DUO.
The proposed insertable stream allows to insert a TransformStream that modifies (un)encoded streams at sender and receiver:

It allows implementing the same logic as the native libwebrtc frameEncryptor API, but in javascript. Most likely, Google already has a JS implementation of Sframe in JS.

Those insertable streams are available as an origin field trial extension, which means that you can enable them through chrome://flag, or for a given domain by registering the experiment and adding the token on the web page.
It should work on canary, if provided with the following command line flags
-enable-experimental-web-platform-features
-force-fieldtrials=WebRTC-GenericDescriptorAdvertised/Enabled/
If you have followed our technical discussion above, you should realise that the second flag is NOT needed if you use VP9.
A JS example is available in the webrtc/sample repository. A better example, closer to the SFrame implementation was provided by Sergio, but eventually not added (*). The entire discussion, including the better example, can be read here.
More interestingly, an SFrame capable Medooze media server is available for testing! Note the emphasis on “PUBLIC” as we have been at work on those matters for more than 3 years now.
Conclusion
This post has introduced end-to-end media encryption, and provided corresponding working examples, including an SFU. This is however but a piece of the puzzle.
For industrial-strength E2EE, the design of the key management, rotation and distribution is maybe even more important than the media encryption itself. After all, why using an armoured door with the most secure lock, if the key is under the mattress and a sign on the door says “the look is under the mattress” There, the most promising technology is MLS. However, with a limit at 50k participant, it might not be enough as-is for naive streaming platforms.
Some assumptions in the document above were made about the maximum number of users in a call, which would not e true for streaming and broadcast for example. Intuitively, the higher the number, the more bits you need to use, increasing the bandwidth overhead.
Also, End-to-end encryption is a feature that will impact your entire system!
To take only two examples of disrupted features: Broadcasting and Recording.
With double encryption, media servers cannot record media files, since the content is still encrypted by the E2E key it doe snot have access to. Any recording feature need to be re-design for encrypted storage, and secure replay, which requires some black magic with key management (how to retrieve the key that was used during the original recording, what about if yes are being rotated during the recording, who should be able to replay this file, ….).
Most of the media servers used for streaming and broadcast out there use transcoding, either because either because the main protocol (HLS, MPEG-DASH, …) uses ABR for bandwidth adaptation, or because they are changing protocols on the way (RTMP ingest). With encrypted content, there is no transcoding possible anymore. Platforms like millicast.com, which leverages simulcast and SVC instead of ABR, support E2EE out of the box, most of the other platforms will have to re-design.
E2EE is going to become a needed feature, a must-have and not a differentiator. We can help you upgrade your webrtc solution to leverage end-to-end encryption, or bootstrap in full secure mode. If you are a PaaS and you want to add that extra layer for your customer, contact us!



")