


We often think of audio data as just data we interpret and process through our auditory system, but that doesn’t have to be the only way that we analyze and interpret audio signals. One such way we can instead understand audio data is through visual representations of the noises we hear. These visual representations are most commonly represented in a waveform plot where we visualize sound pressure in relation to time.
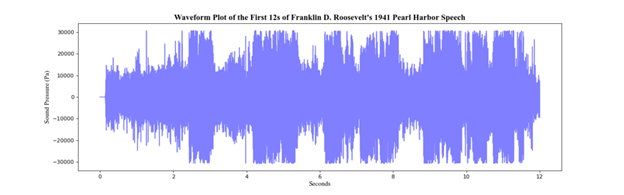
This representation, whilst sufficient, often oversimplifies audio data, which is more than just sound pressure over time. This is where we introduce the spectrogram. A spectrogram is a representation of frequency over time with the addition of amplitude as a third dimension, denoting the intensity or volume of the signal at a frequency and a time.
Why use a spectrogram?
Visualizing data with a spectrogram helps reveal hidden insights in the audio data that may have been less apparent in the traditional waveform representations, allowing us to distinguish noise from the true audio data we wish to interpret. By visualizing audio data this way we can get a clear picture of the imperfections or underlying issues present, helping to guide our analysis and repair of the audio.
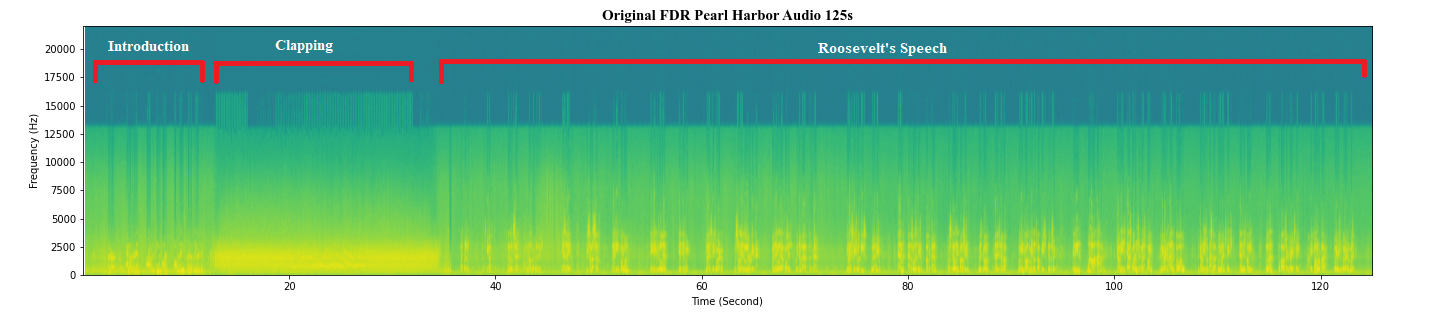
The utility of the spectrogram is best highlighted through an example. Pictured is a 125-second sample of a traditionally noisy audio recording, taken from Franklin D. Roosevelt’s 1941 speech following the surprise attack on Pearl Harbor, represented as a spectrogram. This antiquated audio sample is rife with noise and low quality when compared to modern audio samples. Despite this, we can still get a picture of what is going on in the audio sample, with the first 15 seconds being an introduction by the host, further away from the microphone, followed by 20 seconds of clapping, finally followed by the start of Roosevelt’s speech where we can see spikes in intensity and frequency as the then-president announces and responds to the attack. By first visualizing the data this way we get a picture of what improvements can be made to the audio as many of Roosevelt’s spoken words blur together in the representation, suggesting the presence of noise.
Visualizing Dolby.io Media Enhance
One such strategy for improving the quality of this audio sample is through the use of the Media Enhance API present on Dolby.io. The Media Enhance API works to remove the noise, isolate the spoken audio, and correct the volume and tone of the sample for a more modern representation of the speech. To use this feature yourself you can follow the steps included below or skip to the bottom where we show off the results.
To start the visualization process we first need an audio file to enhance. You can use your own or find some examples here. After picking your audio file. Dolby.io supports many formats but we’ll use a WAV file to create an enhanced version. See the Enhancing Media tutorial to learn how.
1 – Install and Import Dependencies
There are a few Python packages we need to import. You’ll need to install numpy, matplotlib, and scipy into your Python environment.
# for data transformation
import numpy as np
# for visualizing the data
import matplotlib.pyplot as plt
# for opening the media file
import scipy.io.wavfile as wavfile2 – Read and Trim File
Utilizing SciPy’s wavfile function we can extract the relevant data from the WAV file and load it into a NumPy data array so we can trim to an appropriate length.
Fs, aud = wavfile.read('pearl_harbor.wav')
# select left channel only
aud = aud[:,0]
# trim the first 125 seconds
first = aud[:int(Fs*125)]You’ll notice that when we load the WAV file SciPy’s function returns two elements the Sample Rate (fs) and the data (aud). It’s important to keep both of these values as we will need them to create the spectrogram.
3 – Generate Spectrogram
In this example we won’t focus on the Matplotlib style elements, rather we will focus on plotting the spectrogram, with the additional stylings such as fonts, titles and colors available with the full code artifact here. To plot the spectrogram we call Matplotlib’s specgram function along with the .show() function to project the plot:
powerSpectrum, frequenciesFound, time, imageAxis = plt.specgram(first, Fs=Fs)
plt.show()Following these steps we should see something similar to the below plot, albeit truncated without Matplotlib’s styling elements.
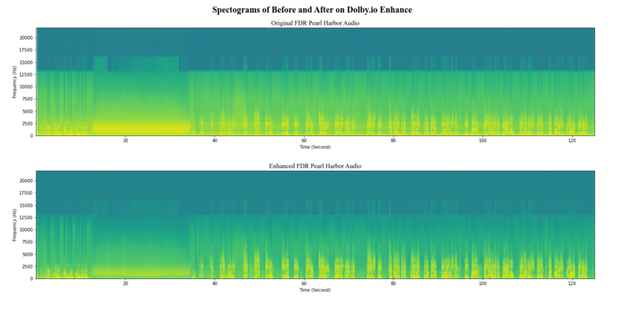
When pictured in succession, the impact of the Media Enhance API is apparent in the spectrogram representation of the sample. The enhanced plot includes more isolated and intense spikes when Roosevelt speaks, followed by a dramatic contrast in intensity where Dolby.io has minimized the noise. This leads to a far cleaner audio experience as Roosevelt’s words blend less with the background noise, becoming more distinct and legible to the listener.
Conclusion
By representing audio data in this way we provide an extra dimension to our analysis, allowing for a more calculated approach to audio corrections and enhancement, highlighting the utility of spectrograms, and visually representing audio data. This approach to audio data analysis has been used in a number of industry and academic applications including speech recognition with recurrent neural networks, studying and identifying bird calls, and even assisting deaf persons in overcoming speech deficits. Additionally, through the use of Dolby.io, we can visually see the effectiveness of the Enhance feature and how it is able to isolate and improve audio quality for a more seamless listening experience.
Interested in extracting Data from your Media? Check out this guide on using APIs to Analyze and Extract Media Data.




")