



What is Sibilance?
Simply stated, sibilance are the essss-sounds in a phrase like ‘six snakes silently sipping.’ It is a normal and essential part of speech. Without sibilance, you wouldn’t be able to hear the difference between the words “beach” and “speech.”
What Causes It?
Sibilance (and other ‘fricative’ vocal sounds) are caused by turbulent airflow as the breath passes through a narrow opening, in this case, between the tongue and teeth. They are heard as a brief burst of high-frequency sound.
Sibilance can be exaggerated by common audio tools and practices. Professional microphones and vocal processing chains are often designed to emphasize high-frequency clarity. This is helpful to add crispness and intelligibility to speech, especially when music or other background sounds are part of the mix.
Depending on the talker, these sibilant noise bursts can become distracting, or even annoying.
Addressing the Problem
Let’s listen to a speech recording with fairly obvious sibilance.
In this video, you can listen to the speech while the scrolling cursor highlights a visual representation of the audio waveform. Peaks in the waveform display indicate louder sounds. In particular, notice the loud “ess” sound in “without sibilance…” and “speech”.
One approach to sibilance is to avoid it in the first place. For a good introduction on sibilance control for voice talent, check out What is Vocal Sibilance and How To Get Rid of It! by voice over coach Gabby Nistico.
Besides working with your voice talent to minimize undesired sibilance, signal processing tools can help. One could use an equalizer (aka EQ) to reduce higher-frequency sounds of your entire speech track. But this can reduce intelligibility, as it applies processing even where it is not necessary.
Rather than applying static processing over the entire track, it’s better to have a dynamic tool which detects sibilance and selectively turns down higher frequencies for just those moments. (You may have heard the term “de-esser”. This describes an audio process which dynamically reduces “esss” sounds.)
The Dolby.io Media Enhance API can target sibilance with four different reduction amounts:
- low
- medium
- high
- max
You’ll find this parameter in the Media Enhance reference documentation under audio > speech > sibilance.
Now, let’s listen to the same recording, enhanced using the Dolby.io media processing tool. In this example, only the sibilance process has been enabled and is set to “medium.”
With a little listening practice you should be able to hear the difference, even though the processing is only applied sporadically. See Developing Listening Skills for Audio Speech Content for listening tips.
This image can help illustrate the change between the original and “medium” processed sound:
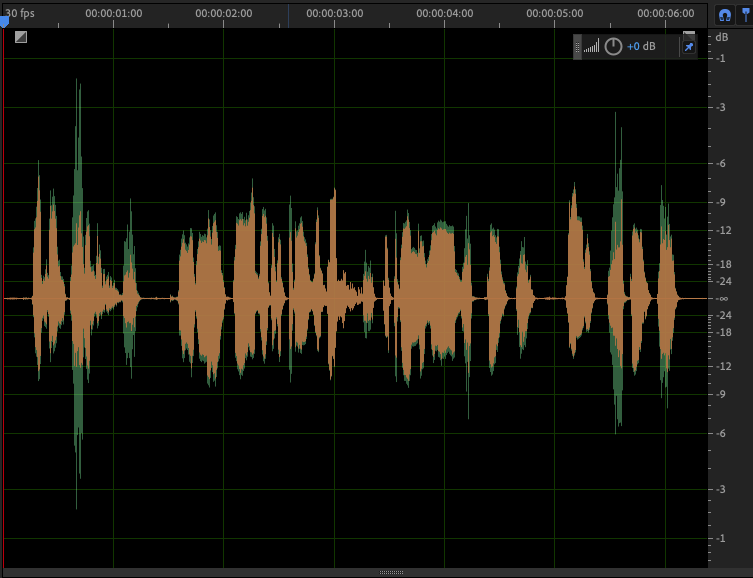
In the image above, the green shows the original waveform while the orange overlay indicates the processed speech. The difference in the waveform for the first word shows how much the volume of the “ess” sounds were reduced. Similar corrections can be seen throughout the clip.
It is important to note that sibilance reduction is most effective on speech-only recordings. Once the dialog has been combined with music or sound effects, de-essing algorithms may get applied to non-speech sounds which happen to have bursts of loud high frequencies.
Jupyter Notebook
Here’s a few examples of how this processing was done in a few steps from an accompanying Jupyter notebook. To gain access, you can check out the GitHub repository.
Step 1
# prepare your API key and get a pre-signed URL before uploading your audio file for enhancing
# see https://dolby.io/developers/media-processing/quick-start/analyzing-media#1-get-your-api-key
import os
import requests
import shutil
import time
api_key = os.environ["DOLBYIO_API_KEY"]
local_audio_files = '~/samples'
source_recording = 'beach_and_speech.wav'
file_path = os.path.join(local_audio_files,source_recording)
uploaded_file = 'dlb://in/example.wav'
processed_file = 'dlb://out/processed.wav'
# Declare your dlb:// location
url = "https://api.dolby.com/media/input"
headers = {
"x-api-key": api_key,
"Content-Type": "application/json",
"Accept": "application/json",
}
body = {
"url": uploaded_file,
}
response = requests.post(url, json=body, headers=headers)
response.raise_for_status()
data = response.json()
presigned_url = data["url"]
print(f'your pre-signed_url is {presigned_url}')Step 2
# Upload your media to the pre-signed url response
# See https://dolby.io/developers/media-processing/quick-start/analyzing-media#2-upload-media
print(f"Uploading {file_path} to your pre-signed_url")
with open(file_path, "rb") as input_file:
requests.put(presigned_url, data=input_file)Step 3
# Process the audio.
# see https://dolby.io/developers/media-processing/quick-start/enhancing-media#3-make-an-enhance-request
# In this example, we are explicitly disabling ALL
# types of processing EXCEPT sibilance control, so you can more easily
# compare the before and after examples. In practice, you would probably
# enable loudness and dynamics processing at a minimum.
body = {
"input" : uploaded_file,
"output" : processed_file,
"content":
{ "type": "voice_over" },
"audio": {
"loudness": { "enable" : False },
"dynamics": { "enable" : False },
"filter": { "high_pass": { "enable": False } },
"noise": { "reduction": { "enable": False } },
"speech": {
"sibilance": {"reduction": {"amount": "medium"}},
"isolation": {"enable": False}
}
}
}
url = "https://api.dolby.com/media/enhance"
headers = {
"x-api-key": api_key,
"Content-Type": "application/json",
"Accept": "application/json"
}
response = requests.post(url, json=body, headers=headers)
response.raise_for_status()
data = (response.json())
job_id = data["job_id"]
print(f' Returned job_id is: {job_id}')Step 4
# Check job status
# see https://dolby.io/developers/media-processing/quick-start/analyzing-media#4-check-the-results
url = "https://api.dolby.com/media/enhance"
headers = {
"x-api-key": os.environ["DOLBYIO_API_KEY"],
"Content-Type": "application/json",
"Accept": "application/json"
}
params = {
"job_id": job_id
}
print('waiting for job status == Success ', end='')
while True:
response = requests.get(url, params=params, headers=headers)
response.raise_for_status()
data = response.json()
# Would be good to also check for errors
# but keeping it simple
if (data.get('status') == 'Success'):
print('Success')
break
print('.', end='')
time.sleep(2)Step 5
# Download the processed audio file
# https://dolby.io/developers/media-processing/quick-start/enhancing-media#5-review-media
output_path = os.path.join(local_audio_files, 'beach_and_speech_sibilance_medium.wav')
url = "https://api.dolby.com/media/output"
headers = {
"x-api-key": os.environ["DOLBYIO_API_KEY"],
"Content-Type": "application/json",
"Accept": "application/json",
}
args = {
"url": processed_file
}
with requests.get(url, params=args, headers=headers, stream=True) as response:
response.raise_for_status()
response.raw.decode_content = True
print("Downloading from {0} into {1}".format(response.url, output_path))
with open(output_path, "wb") as output_file:
shutil.copyfileobj(response.raw, output_file)Conclusion
Correcting sibilance is just one of the elements within the Dolby.io media toolchain. While it may be a more subtle enhancement than loudness and dynamics processing, don’t overlook its value as you strive towards the clearest, best-sounding speech you can offer your audience.





")